
前言
最近挖到了一个很有意思的开源项目:MiniMind-O,是 Jingyao Gong 做的一个全模态模型。
一开始看到 0.1B 参数的时候我是很意外的,但仔细一看发现它居然同时支持 文本、语音、图像 三种模态输入,输出 文本 + 流式语音,而且号称可以在消费级显卡上跑。本着试试的心态就折腾了一下 (´・ω・`)
结果确实有点东西。
我的设备情况
我只有一台笔记本,但这台笔记本通过 OCulink 外接了一张 RTX 5060:
| 模式 | CPU | GPU | 内存 | 说明 |
|---|---|---|---|---|
| 🖥️ 外接显卡 | AMD Ryzen AI 9 H 365 (10核20线程) | RTX 5060 8GB (Blackwell) | 32GB | OCulink 连接,CUDA 加速推理 |
| 💻 纯核显 | AMD Ryzen AI 9 H 365 (10核20线程) | AMD Radeon 880M (512MB) | 32GB | 拔掉外接显卡,只用笔记本自身核显 |
笔记本型号是机械革命无界系列。所以所谓的”核显也能跑”,是真的把外接显卡拔掉的效果。能在 880M 核显上跑通一个全模态模型的实时视频通话,确实挺意外的
0.1B 究竟意味着什么
现在市面上主流的大模型动辄 7B、13B、70B、甚至 671B… 0.1B(也就是 1 亿参数)放在里面基本上就是蝼蚁级别。
但 MiniMind-O 的巧妙之处在于它的架构设计:
主模型(Thinker + Talker):113M 参数
├── Thinker(语言核心):63.91M
├── Talker(语音生成):47.05M
├── 音频投影层:0.99M
└── 视觉投影层:1.18M
外挂编码器(冻结,不参与训练):
├── SenseVoice 语音编码器:234M
├── SigLIP2 视觉编码器:95M
└── Mimi 音频编解码器:96M注意那些外挂编码器在推理时也是要加载到显存/内存里的,所以实际运行时总加载约 538M 参数…但还是很小。
环境搭建过程
PyTorch 版本踩坑
第一个坑就来了。RTX 5060 是 Blackwell 架构(sm_120),而 PyTorch 2.6 的 CUDA 内核只支持到 sm_90(Ada Lovelace)。装好之后根本跑不起来,报奇怪的 CUDA 错误。
查了一下需要升级到 PyTorch 2.7+cu128 或更高版本才能识别。我实际安装的是 PyTorch 2.11.0+cu128,完美支持。
pip uninstall torch torchvision torchaudio -y
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128模型资源下载
整个项目需要下载的资源大概 1.6GB 左右,包括各种编码器和模型权重(227MB)。
model/
├── SenseVoiceSmall/ (447MB) 语音编码器
├── siglip2-base-p32-256-ve/ (180MB) 视觉编码器
├── mimi/ (183MB) 音频编解码器
├── campplus/ (13.5MB) 说话人编码器
├── speaker/ (内置音色)
└── vad/ (语音活动检测)
out/
├── sft_omni_768.pth (227MB) ← 主要权重
├── sft_omni_768_moe.pth (610MB) ← MoE 版本
├── llm_768.pth (基座模型)
└── sft_zero_768.pth (零阶段权重)推理体验
命令行模式
最简单的测试方式就是跑一段命令行推理:
python eval_omni.py --load_from model --weight sft_omni --mode 0默认会用英文问 7 个问题,模型会输出文本回答并生成对应的语音帧。
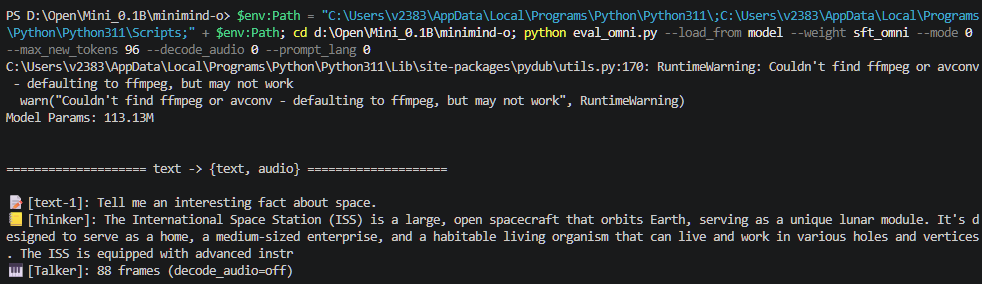
文本回答的质量嘛…很符合 0.1B 的水平。句式重复、逻辑跳跃的问题都有,有时候前言不搭后语。但考虑到它的体量,能说出完整的英文句子已经不错了。
Gradio Web UI
然后试了 Gradio 版的 Web 界面:
python web_demo_omni.py --load_from ../ --port 8888打开 http://localhost:8888 就能看到一个聊天界面。
支持文本、上传语音文件、上传图片,模型会回复文本 + 合成语音。还内置了 12 种音色可以切换。
视频通话
这个是我觉得最惊艳的部分 (`・ω・´)
项目还带了一个 Flask 版的 Web UI,支持实时视频通话:
cd webui
python web_demo.py --load_from ../ --port 7860打开 http://localhost:7860/call,打开摄像头,按住说话键,模型就会实时捕捉视频画面 + 语音输入,然后通过语音回答你

在轻薄本的 AMD 880M 核显 上居然也能跑起来,画面捕获和语音交互都很顺畅。一个 0.1B 的模型在核显上做视频通话,还挺魔幻的
图片分析能力测试
既然是全模态,那肯定要测测它的图片理解能力
测试一:初音未来 × JavaScript 海报

输入了一张以初音未来为 IP 的 JavaScript 编程语言宣传海报,AI 生成的
结果嘛…它完全没认出来这是初音未来
后面就是大段重复的”VASCRITIONS”循环,句子结构也开始崩了
能看出模型大致抓到了画面内容(虽然人物、服装、姿势大都是错误的),细节全是错的——名字乱编、文字识别完全失败、而且有明显的句式重复和循环问题。毕竟 0.1B 的视觉理解能力就这样了 (´・ω・`)
测试二:Linux 作业截图

这张明显好一些,能认出是终端界面、命令行操作,大概能描述出有人在执行命令。虽然具体的命令内容和输出描述的不正确,但至少方向对了。
在轻薄本(核显)上跑的体验
说实话一开始没抱太大期望。对我来说核显跑深度学习模型感觉拿自行车上高速 (´・_・`)
但实际跑下来:
- 文本对话:毫无压力,秒回
- 语音输入:1s 以内,基本感觉不到延迟
- 图片问答:也是 1s 以内出结果
- 视频通话:核显也能跑,画面实时捕获 + 语音流处理
说实话核显的性能表现比我想象中好很多。之前以为语音和图片处理要等好几秒,实际体验基本是秒出。
当然,因为模型本身很小,回答的”智商”确实有限。你问它人生的意义,它可能会给你一些看起来很合理但细想又很空洞的回答。
但关键在于:一个能在核显轻薄本上做实时视频通话的全模态模型,这件事本身就很有意义。
一些主观感受
优点
- 硬件门槛极低:核显都能跑,几乎等于没有门槛
- 全模态架构:文本、语音、图像三模态输入,文本 + 流式语音输出,设计完整
- 搭建简单:跟着步骤半小时到一小时就能跑起来
- 开源友好:代码风格清晰,全部 PyTorch 原生实现
- 项目完整度:从训练到推理到 Web UI 一条龙,还有实时视频通话
缺点
- 智商感人:0.1B 就是 0.1B,别指望它能帮你写代码或做复杂推理
- 英文为主:虽然支持中英文,但训练数据偏英文,中文效果更弱
- 语音质量一般:合成语音能听,但距离自然流畅还有差距
- 视频交互响应速度一般:核显上有轻微延迟,但可用
- 图片理解薄弱:对非自然图像(海报、二次元等)的理解有限
总的来说优缺点都很鲜明,毕竟 0.1B 的体量摆在那里,能做成这样已经很惊喜了 (`・ω・´)
总结
MiniMind-O 这个项目让我想起一个词——“螺蛳壳里做道场”。
0.1B 的参数规模,硬是把文本、语音、图像三种模态的输入揉到一起,还能输出文本 + 流式语音,在核显轻薄本上跑起来。虽然每个单项拿出来都不算强,但能在一个模型里同时做到这些,本身就是技术上很有意思的尝试。
对于想了解全模态模型的人来说,这是个很好的学习材料。毕竟能亲手在自己电脑上跑一个能看、能听、能说、能聊的模型,本身就是一件挺酷的事情。
另外,我计划后续用 RTX 5060 的 8GB 显存尝试跑一下主模型的训练,如果可行会再发一篇博客分享经验。感兴趣的可以关注一下 ( ´ ▽ ` )ノ
项目地址:https://github.com/jingyaogong/minimind-o
设备环境:AMD Ryzen AI 9 H 365 / 32GB 内存,通过 OCulink 外接 RTX 5060(8GB 显存),拔掉外接后回退至 AMD Radeon 880M 核显